The Do It Yourself 99.999% Availability Guide
Migrating workloads to the cloud, AWS customers encounter many questions regarding resilience, availability, and fault tolerance. In this article, I expose the weak spots of cloud-native and, thus, distributed applications in terms of resilience and provide solution options for each one. Traditional data centers provide uptime guarantees for their servers and network, a practice also common for virtually any AWS service. However, in contrast to traditional data centers, cloud providers have a different design focus for their infrastructure. Cloud providers optimize their offerings, like databases, to be easy to repair, whereas traditional data centers aim for maximum uptime. Therefore, the failure tolerance and resiliency of cloud applications must be top priorities. Applications should be designed with these requirements in mind to successfully host them in the cloud. For instance, Amazon RDS (Relational Database Service) allows for replication across multiple Availability Zones, enhancing database resilience and uptime without manual intervention.
Running Example
Let’s begin with a running example that I will use throughout this article. The image below illustrates an artificial architecture of an online shop on the left, including systems responsible for payment (Payment Service) and delivery (Delivery Service). We assume initially that one instance of each service is running in the cloud. All services are cloud-native apps, as defined by the 12-factor app methodology (https://12factor.net), running in a single Amazon AWS region. All communication is REST-based.
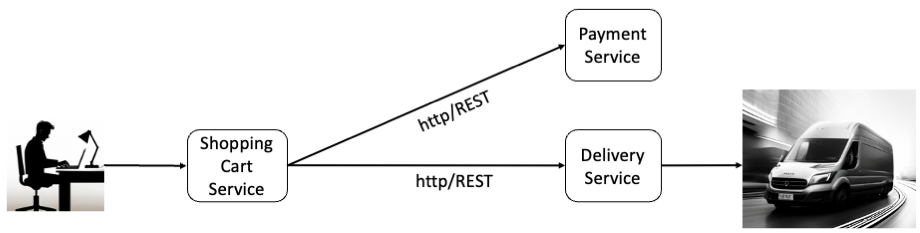 Image 1: Running example
Image 1: Running example
With this setup, customers can select products, place them into the shopping cart managed by the Shopping Cart Service, and initiate a workflow to purchase the products in the cart. This process involves the Payment Service to handle payment and the Delivery Service to manage delivery.
Murphy’s law states, “Anything that can go wrong will go wrong.” With only one instance of each service running, several potential failures can occur. Below, I describe each failure scenario and propose possible countermeasures, focusing primarily on the Delivery Service.
Instance Failures
Failure of the Delivery Service software can cause all invocations to fail immediately. A possible solution is to run multiple instances to enhance resilience. To distribute requests from the Shopping Cart Service evenly, a Load Balancer is necessary (see Image 2). There are two types of load balancers: middleware components such as Application Load Balancer (ALB) and client-side load balancers. With this setup, every Delivery Service instance must be capable of processing all incoming requests, affecting its internal architecture. For example, it’s not feasible for a Delivery Service instance to maintain sessions with the Shopping Cart Service since each request might be routed to different Delivery Service instances. The goal is to design the Delivery Service so that shutting down one or more instances won’t significantly impact its ability to process requests.
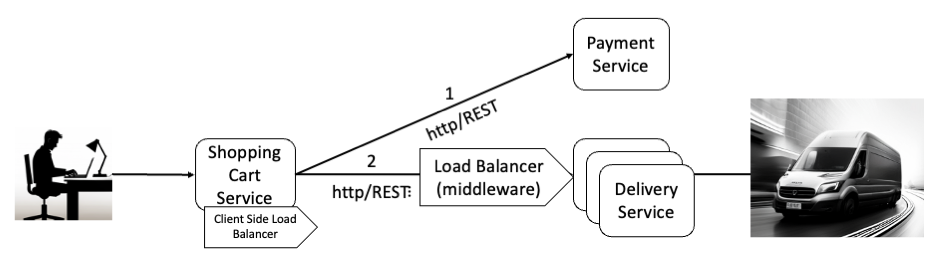 Image 2: Load balancers distribute requests evenly to all instances of
the Delivery Service
Image 2: Load balancers distribute requests evenly to all instances of
the Delivery Service
Besides running additional instances for resilience, the Shopping Cart Service can implement the circuit breaker pattern. This pattern involves temporarily reducing requests to the Delivery Service upon detecting slower response times and resuming normal operation after a predefined interval, assessing whether the Delivery Service has recovered (https://martinfowler.com/bliki/CircuitBreaker.html).
Another potential failure is the loss of an entire cloud availability zone hosting the Delivery Service. Cloud vendors offer availability zones to enhance application availability. Distributing application instances across multiple zones can mitigate the impact of a zone failure, with load balancers in place to detect and reroute traffic in the event of a regional outage (see Image 3).
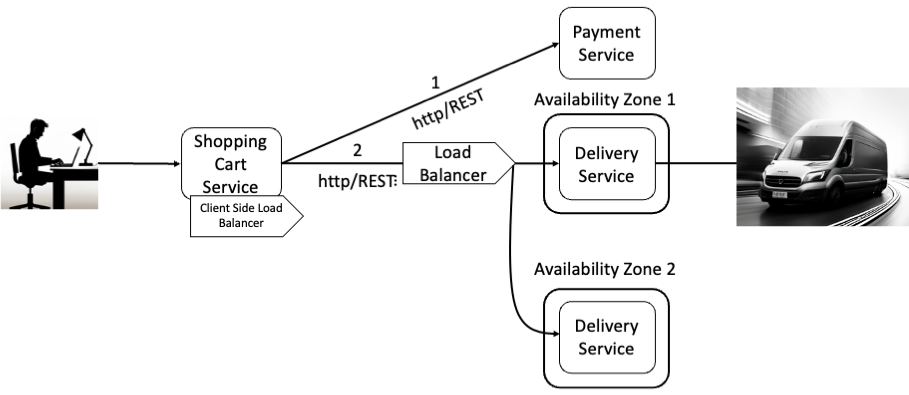 Image 3: Addition of Availability Zones
Image 3: Addition of Availability Zones
Network Failures
To address network failures, the Shopping Cart Service must maintain communication with the Delivery Service, achievable through message-oriented middleware (MOM) (see Image 4). MOM systems, such as queuing and publish-subscribe systems, facilitate reliable messaging between services, with queues serving as buffers to manage message flow. Amazon SQS (Simple Queue Service) and Amazon SNS (Simple Notification Service) are prime examples of MOM systems, facilitating reliable messaging between services, with queues serving as buffers to manage message flow.
Image 4 shows a message queue being set in place between the Shopping Cart Service and the Delivery Service. We don’t need the load balancer in between because the instances of the Delivery Service can process messages when they are able to.
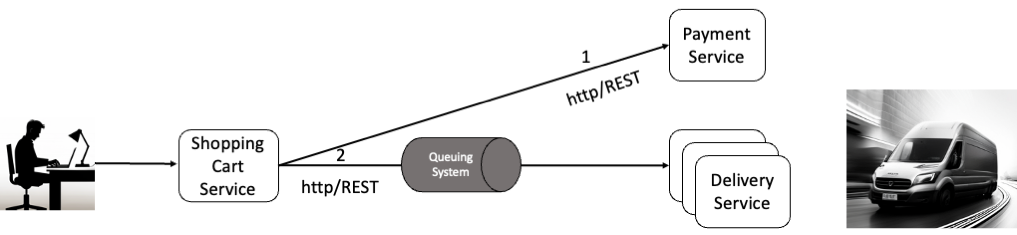 Image 4: Introduction of queuing system
Image 4: Introduction of queuing system
Thus, they are not overwhelmed by incoming messages because the message queue acts as a buffer for them. With the addition of the message queue the Shopping Cart Service can send messages to the Delivery Service even in the rare case the Delivery Service is not available due to a network outage.
Working with Service Level Agreements (SLAs)
Managing microservices in the cloud involves planning for unplanned downtimes. Although downtimes are inevitable, they can be managed within the downtime budget defined in each microservice’s SLA. For instance, the Shopping Cart Service could have a companion microservice to store and retry pending requests to the Delivery Service, ensuring minimal customer impact. Teams should strive to meet their SLAs precisely, avoiding reliance on better-than-expected uptime.
Compensating Actions
For extended downtimes that threaten SLA compliance, the Delivery Service team could implement compensating actions, such as offering vouchers to affected customers, to maintain customer satisfaction.
Conclusion
Implementing the measures outlined above can significantly improve system uptime, challenging the notion that service downtimes must be cumulatively calculated. The introduction of a message queue between services and the resilience of the companion service ensure that the system remains functional and responsive, even during service disruptions.
Do you have further ideas on making a cloud application more reliable? We would love to read it in the comments!